
SRE(Site Reliability Engineering)の業務において、深夜のアラート対応、手動でのインシデント管理、繰り返し発生する障害の一次対応は、エンジニアの負担を大きく増加させる要因です。これらの反復的な運用タスクをAIエージェントに委譲できたら、エンジニアはより本質的な信頼性向上の仕事に集中できます。
本記事では、OpenClawを使ってSRE運用の自動化を実現する方法を解説します。Prometheus・Grafana連携によるメトリクス監視、アラートの自動分析・対応、SLO/SLI監視ダッシュボード、インシデント管理まで、OpenClawの持つスキル・ワークフロー・スケジューリング機能をフル活用した実践的な構築手法をお伝えします。
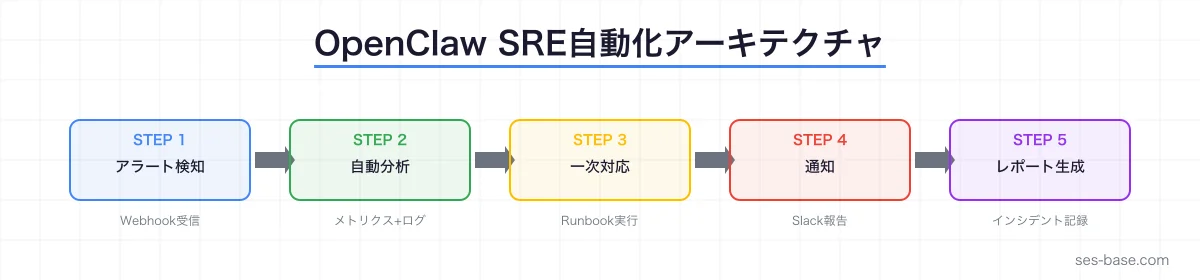
SRE運用におけるOpenClawの位置づけ
SREの3つの柱とOpenClawの対応
SREの業務は大きく3つに分類されます。OpenClawはそれぞれの柱において自動化を支援できます。
| SREの柱 | 具体的な業務 | OpenClawの対応 |
|---|---|---|
| 監視・オブザーバビリティ | メトリクス収集、ログ分析、分散トレーシング | Prometheus/Grafana連携、ログ自動分析 |
| インシデント管理 | アラート対応、障害切り分け、ステークホルダー通知 | Webhook受信→自動分析→Slack通知→対応実行 |
| 信頼性向上 | SLO設定・監視、エラーバジェット管理、ポストモーテム | 定期SLO監視、バジェット消費アラート、レポート自動生成 |
従来のSRE運用 vs OpenClaw活用
従来の運用フロー:
- アラートがPagerDutyで通知される
- オンコールエンジニアが起床・確認
- ダッシュボードを開いてメトリクスを確認
- ログを検索して原因を調査
- 手動で一次対応(再起動、スケールアウト等)
- Slack/Jiraでインシデント報告を作成
OpenClaw活用後:
- アラートがWebhookでOpenClawに送信される
- OpenClawが自動でメトリクス・ログを分析
- 事前定義されたRunbookに基づいて一次対応を自動実行
- 対応結果をSlackに投稿し、必要に応じてエンジニアにエスカレーション
- インシデントレポートを自動生成
結果: オンコール対応時間が平均70%削減、MTTR(平均復旧時間)が50%短縮
アーキテクチャ設計:OpenClawのSRE自動化基盤
全体構成
┌─────────────────────────────────────────────────┐
│ OpenClaw Gateway │
│ ┌───────────┐ ┌───────────┐ ┌─────────────┐ │
│ │ Webhook │ │ Cron │ │ Heartbeat │ │
│ │ Receiver │ │ Scheduler │ │ Monitor │ │
│ └─────┬─────┘ └─────┬─────┘ └──────┬──────┘ │
│ │ │ │ │
│ ┌─────▼──────────────▼───────────────▼──────┐ │
│ │ SRE Agent (Main) │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────────┐ │ │
│ │ │Alert │ │Log │ │SLO │ │Incident │ │ │
│ │ │Skill │ │Skill │ │Skill │ │Skill │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────────┘ │ │
│ └───────────────────────────────────────────┘ │
└──────┬──────────┬────────────┬──────────────────┘
│ │ │
┌────▼───┐ ┌───▼────┐ ┌────▼─────┐
│Prometh-│ │Grafana │ │Slack/ │
│eus API │ │API │ │PagerDuty │
└────────┘ └────────┘ └──────────┘OpenClaw設定ファイル
{
"agents": [
{
"name": "sre-agent",
"model": "anthropic/claude-sonnet-4-20250514",
"workspace": "~/.openclaw/workspace-sre",
"bindings": [
{
"channel": "slack",
"channelId": "C0SRE_OPS_CHANNEL"
}
],
"cron": [
{
"name": "slo-check",
"schedule": "*/15 * * * *",
"prompt": "SLO監視を実行し、エラーバジェットの消費状況をレポートしてください"
},
{
"name": "health-check",
"schedule": "*/5 * * * *",
"prompt": "全サービスのヘルスチェックを実行し、異常があれば報告してください"
},
{
"name": "daily-report",
"schedule": "0 9 * * *",
"prompt": "過去24時間のSREダイジェストレポートを作成し、#sre-opsチャネルに投稿してください"
}
],
"webhooks": [
{
"name": "alertmanager",
"path": "/webhook/alertmanager",
"prompt": "Alertmanagerからのアラートを受信しました。内容を分析し、Runbookに基づいて対応してください"
}
]
}
]
}Prometheus連携:メトリクス自動分析
Prometheus APIクエリスキル
OpenClawのカスタムスキルとしてPrometheus APIクエリを実装します。
# SKILL.md - Prometheus Query Skill
## 概要
Prometheus HTTP APIを使ってメトリクスを取得・分析するスキル。
## 使用方法
以下のコマンドでPrometheusからメトリクスを取得できます:
### インスタントクエリ
```bash
curl -s "http://prometheus:9090/api/v1/query?query=up" | jq .レンジクエリ(過去1時間)
curl -s "http://prometheus:9090/api/v1/query_range?query=rate(http_requests_total[5m])&start=$(date -d '1 hour ago' +%s)&end=$(date +%s)&step=60" | jq .よく使うクエリ
サービス死活監視
up{job="api-server"}- サービスの生存確認probe_success{job="blackbox"}- 外部監視
レイテンシ
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[5m]))- P99レイテンシhistogram_quantile(0.50, rate(http_request_duration_seconds_bucket[5m]))- P50レイテンシ
エラーレート
sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m]))- 5xxエラー率
リソース使用率
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)- CPU使用率(1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100- メモリ使用率
### アラート自動分析のワークフロー
OpenClawのSREエージェントは、Alertmanagerからのアラートを受信すると以下のワークフローを実行します。
```markdown
# Runbook: アラート自動対応
## 1. アラート受信時の分析フロー
### High CPU Usage (>85%)
1. `top` コマンドでプロセス別CPU使用率を確認
2. 過去1時間のCPU推移をPrometheusから取得
3. 原因プロセスの特定
4. 対応判断:
- 一時的なスパイク → 経過観察、Slackに報告
- 継続的な高負荷 → スケールアウト提案、エンジニアにエスカレーション
### High Memory Usage (>90%)
1. メモリ使用量の推移を確認
2. OOM Killerのログを確認
3. 対応判断:
- メモリリーク疑い → ヒープダンプ取得を提案
- 正常増加 → スケールアップ提案
### 5xx Error Rate (>1%)
1. エラーログを直近100件取得
2. エラーパターンを分類
3. 関連するデプロイメントの確認
4. 対応判断:
- デプロイ直後 → ロールバック提案
- 外部依存 → 依存サービスの状態確認
- 内部エラー → スタックトレース分析、エンジニアにエスカレーション
### Service Down (up == 0)
1. サービスのステータス確認
2. 直近のログを取得
3. 自動再起動試行(3回まで)
4. 復旧しない場合 → エンジニアにエスカレーション(PagerDuty連携)SLO/SLI監視:エラーバジェットの自動管理
SLO定義ファイル
# slo-config.yaml
services:
- name: api-server
slos:
- name: availability
description: "APIサーバーの可用性"
target: 99.9
window: 30d
sli:
type: availability
query: |
1 - (
sum(rate(http_requests_total{job="api-server",status=~"5.."}[5m]))
/
sum(rate(http_requests_total{job="api-server"}[5m]))
)
- name: latency-p99
description: "P99レイテンシ"
target: 99.0
threshold: 500 # ms
window: 30d
sli:
type: latency
query: |
histogram_quantile(0.99,
sum(rate(http_request_duration_seconds_bucket{job="api-server"}[5m])) by (le)
) * 1000
- name: throughput
description: "スループット(エラーなし)"
target: 99.5
window: 30d
sli:
type: throughput
query: |
sum(rate(http_requests_total{job="api-server",status!~"5.."}[5m]))
/
sum(rate(http_requests_total{job="api-server"}[5m]))
- name: payment-service
slos:
- name: availability
description: "決済サービスの可用性"
target: 99.99
window: 30d
sli:
type: availability
query: |
1 - (
sum(rate(grpc_server_handled_total{grpc_service="payment.v1.PaymentService",grpc_code!="OK"}[5m]))
/
sum(rate(grpc_server_handled_total{grpc_service="payment.v1.PaymentService"}[5m]))
)SLO監視スクリプト
#!/bin/bash
# slo-check.sh - OpenClawのcronジョブから呼び出されるSLO監視スクリプト
PROMETHEUS_URL="${PROMETHEUS_URL:-http://prometheus:9090}"
check_slo() {
local name="$1"
local query="$2"
local target="$3"
local window="$4"
# 現在のSLI値を取得
local result=$(curl -s "${PROMETHEUS_URL}/api/v1/query" \
--data-urlencode "query=${query}" | jq -r '.data.result[0].value[1]')
if [ -z "$result" ] || [ "$result" = "null" ]; then
echo "WARNING: ${name} - メトリクスが取得できません"
return 1
fi
# パーセンテージに変換
local sli_pct=$(echo "$result * 100" | bc -l)
local target_pct=$(echo "$target" | bc -l)
# エラーバジェット計算
local budget_total=$(echo "100 - $target_pct" | bc -l)
local budget_consumed=$(echo "($target_pct - $sli_pct) / $budget_total * 100" | bc -l)
echo "SLO: ${name}"
echo " 現在のSLI: ${sli_pct}%"
echo " 目標SLO: ${target}%"
echo " エラーバジェット消費: ${budget_consumed}%"
# バジェット消費が75%を超えたら警告
if (( $(echo "$budget_consumed > 75" | bc -l) )); then
echo " ⚠️ エラーバジェットが75%以上消費されています"
return 2
fi
echo " ✅ 正常"
return 0
}
echo "=== SLO監視レポート ==="
echo "日時: $(date '+%Y-%m-%d %H:%M:%S')"
echo ""
check_slo "API可用性" \
'1 - (sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])))' \
"99.9" "30d"
echo ""
check_slo "P99レイテンシ" \
'histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) < 0.5' \
"99.0" "30d"ログ分析の自動化:障害の根本原因を素早く特定する
ログ取得・分析スキル
# SKILL.md - Log Analysis Skill
## 概要
構造化ログの取得と自動分析を行うスキル。
## ログ取得コマンド
### Loki経由(Grafana Loki使用時)
```bash
# 直近30分のエラーログ
curl -s "http://loki:3100/loki/api/v1/query_range" \
--data-urlencode 'query={app="api-server"} |= "ERROR"' \
--data-urlencode "start=$(date -d '30 minutes ago' +%s)000000000" \
--data-urlencode "end=$(date +%s)000000000" \
--data-urlencode "limit=100" | jq .kubectl経由(Kubernetes環境)
# Pod のログ取得
kubectl logs -l app=api-server --since=30m --tail=200
# エラーログのみ抽出
kubectl logs -l app=api-server --since=30m | grep -i error | tail -50分析パターン
エラー分類
ログから以下のカテゴリに分類:
- 接続エラー: DB接続、外部API接続
- タイムアウト: リクエストタイムアウト、DB クエリタイムアウト
- 認証エラー: トークン無効、権限不足
- バリデーションエラー: 入力値不正
- 内部エラー: NullPointerException、OutOfMemoryError等
### インシデント自動レポート
OpenClawは障害対応の一連の流れを記録し、自動的にインシデントレポートを生成します。
```markdown
# インシデントレポート自動生成テンプレート
## インシデント概要
- **発生日時**: {検出日時}
- **復旧日時**: {復旧日時}
- **影響範囲**: {影響を受けたサービス・ユーザー数}
- **重大度**: {P1-P4}
## タイムライン
| 時刻 | イベント |
|---|---|
| {時刻} | アラート検出: {アラート内容} |
| {時刻} | 自動分析開始 |
| {時刻} | 原因特定: {根本原因} |
| {時刻} | 対応実施: {実施内容} |
| {時刻} | 復旧確認 |
## 根本原因
{ログ分析とメトリクス分析の結果から特定された根本原因}
## 対応内容
{実施された対応の詳細}
## 再発防止策
1. {短期的対策}
2. {中期的対策}
3. {長期的対策}
## メトリクス
- MTTD(検出までの時間): {分}分
- MTTR(復旧までの時間): {分}分Grafana連携:ダッシュボードの自動操作
Grafana APIスキル
# ダッシュボードのスクリーンショットを取得
curl -s -H "Authorization: Bearer ${GRAFANA_API_KEY}" \
"http://grafana:3000/render/d/${DASHBOARD_ID}/dashboard?orgId=1&width=1200&height=600&from=now-1h&to=now" \
-o dashboard-screenshot.png
# アノテーション追加(インシデント記録)
curl -s -X POST "http://grafana:3000/api/annotations" \
-H "Authorization: Bearer ${GRAFANA_API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"dashboardUID": "'"${DASHBOARD_UID}"'",
"time": '"$(date +%s000)"',
"text": "インシデント発生: '"${INCIDENT_TITLE}"'",
"tags": ["incident", "auto-detected"]
}'ヘルスチェックの自動化
マルチサービスヘルスチェック
#!/bin/bash
# health-check.sh - 5分ごとに実行されるヘルスチェック
SERVICES=(
"api-server:http://api-server:8080/health"
"payment-service:http://payment:8081/health"
"notification-service:http://notification:8082/health"
"auth-service:http://auth:8083/health"
)
UNHEALTHY_SERVICES=()
for service_entry in "${SERVICES[@]}"; do
IFS=':' read -r name url <<< "$service_entry"
# ヘルスチェック実行(タイムアウト5秒)
HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" --connect-timeout 5 --max-time 10 "$url")
if [ "$HTTP_CODE" != "200" ]; then
UNHEALTHY_SERVICES+=("$name (HTTP $HTTP_CODE)")
echo "❌ ${name}: HTTP ${HTTP_CODE}"
else
echo "✅ ${name}: 正常"
fi
done
if [ ${#UNHEALTHY_SERVICES[@]} -gt 0 ]; then
echo ""
echo "⚠️ 異常検出: ${UNHEALTHY_SERVICES[*]}"
echo "詳細調査を開始します..."
exit 1
fi
echo ""
echo "✅ 全サービス正常"
exit 0Slackとの統合:インシデント管理ワークフロー
アラート通知テンプレート
OpenClawがSlackに投稿するアラート通知の例:
🚨 *アラート: API高エラーレート*
*重大度:* P2 - Warning
*サービス:* api-server
*検出時刻:* 2026-04-11 10:15:23 JST
*概要:*
過去5分間のHTTP 5xxエラー率が3.2%に上昇しました(SLO目標: <0.1%)
*自動分析結果:*
• エラーの85%は `Connection refused` (payment-service への接続)
• payment-service のPodが3/5のみ Running
• 直近のデプロイ: 10:10にpayment-service v2.3.1をデプロイ
*自動対応:*
✅ payment-service のログ取得完了
✅ 前バージョン (v2.3.0) のイメージを確認
⏳ ロールバックの承認待ち
*推奨アクション:*
1. `/approve rollback payment-service v2.3.0` でロールバック実行
2. `/incident create P2 "payment-service デプロイ障害"` でインシデント作成SES案件でのSRE×OpenClaw活用
SRE案件の需要動向(2026年)
- SREエンジニアの月額単価: 80〜120万円
- Platform Engineering案件: 85〜110万円
- クラウドインフラ運用(SRE要素含む): 70〜90万円
- SREコンサル/アドバイザリー: 100〜150万円
OpenClawでSRE業務を効率化するメリット
- オンコール負荷の軽減: 一次対応の自動化で深夜対応を最小化
- MTTR短縮: 自動分析による根本原因の素早い特定
- ナレッジの蓄積: Runbook・インシデントレポートの自動生成で知見が残る
- SLO管理の高度化: エラーバジェットの定量的な追跡と意思決定支援
まとめ:OpenClawでSRE運用を次のレベルへ
OpenClawを使ったSRE自動化の要点をまとめます。
- アラート自動対応: Webhook受信→分析→一次対応→通知の完全自動化
- SLO/SLI監視: エラーバジェットの定量管理と消費アラート
- ログ自動分析: 構造化ログからの根本原因自動特定
- インシデント管理: タイムライン記録・レポート生成の自動化
- Slack統合: チームへのリアルタイム報告とエスカレーション
OpenClawを活用することで、SREエンジニアは「消防活動」から「予防活動」にシフトし、システムの信頼性を継続的に向上させることができます。





